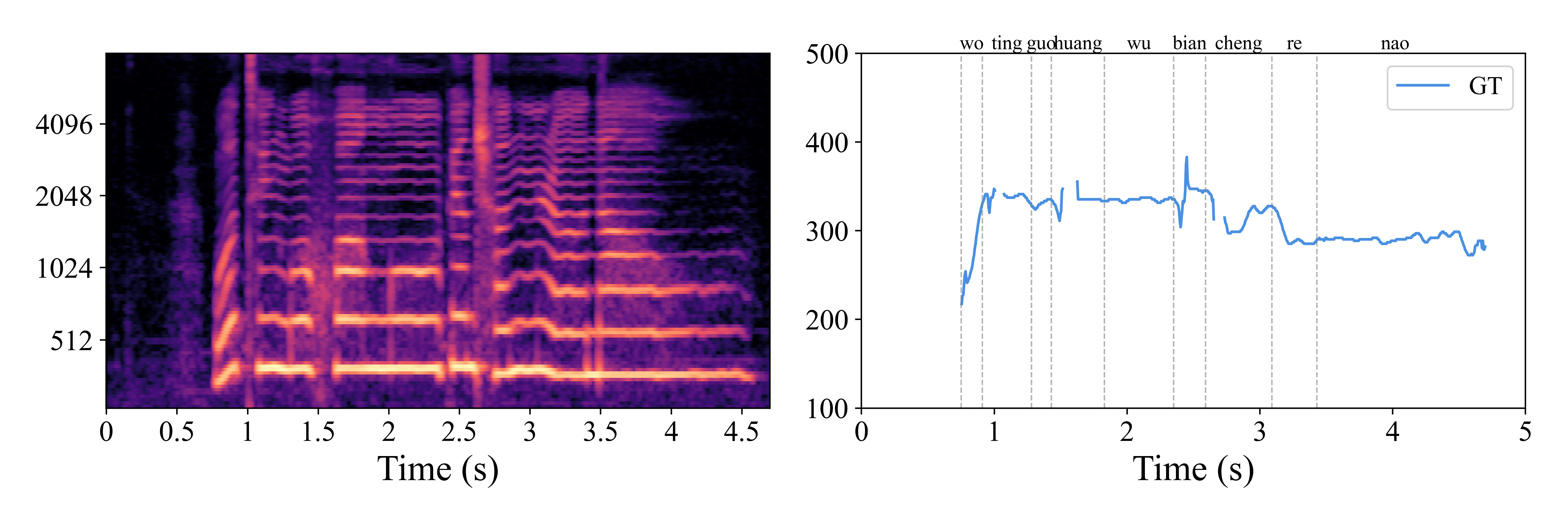
Ground truth pitch contour
The target contour provides the reference structure used to judge melody fidelity.
IEEE Transactions on Audio, Speech and Language Processing · 2026
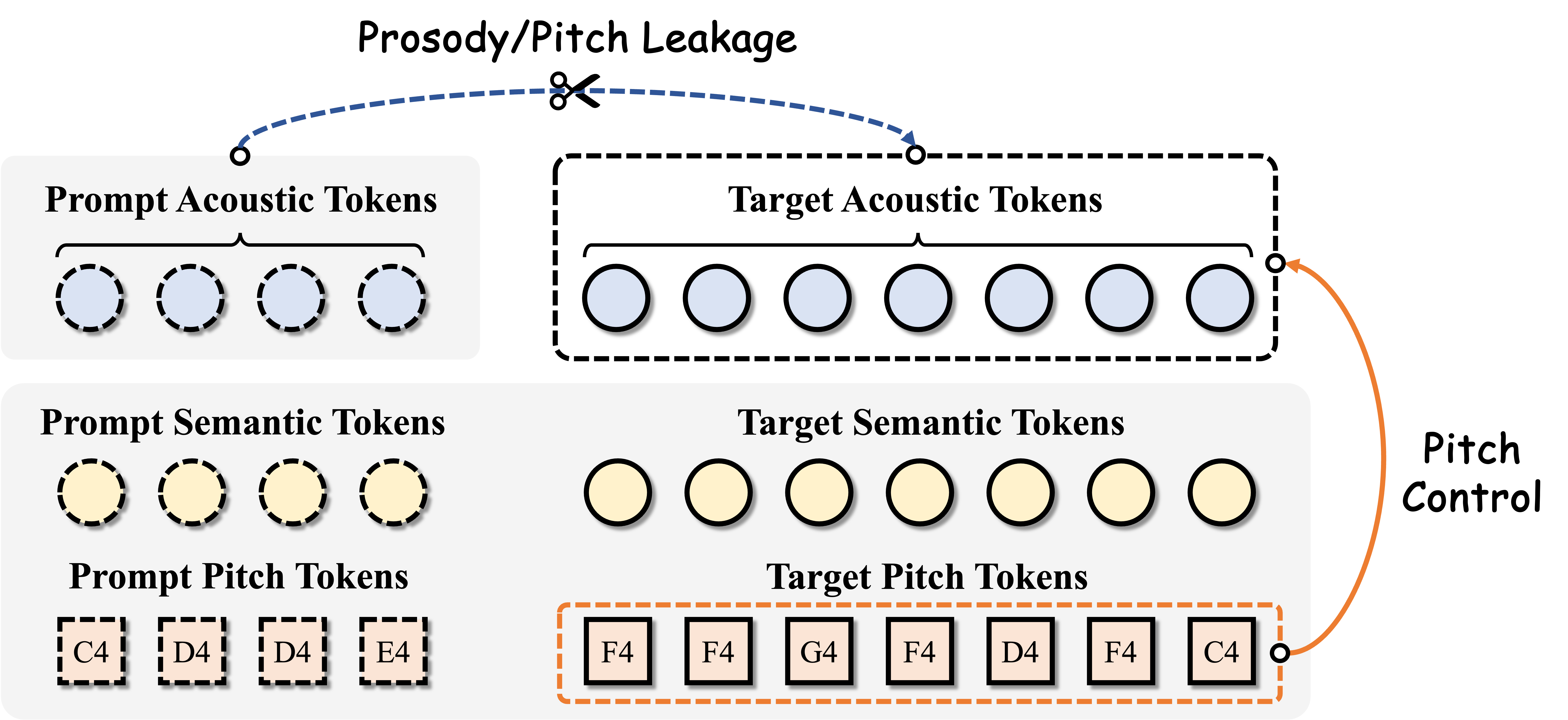
In short: CoMelSinger keeps pitch and timbre on separate threads, so a short reference clip lends its voice — not its melody — to any lyric and pitch sequence you give it.
Zero-shot singing synthesis conditions on a short acoustic prompt to copy a singer's timbre. But pitch and timing ride along in that same prompt, so the model quietly borrows melody from it too — even when an explicit pitch sequence says otherwise.
A Text-to-Semantic stage turns lyrics into semantic tokens. A Semantic-to-Acoustic stage — the only part that's fine-tuned — turns those tokens into singing, steered by an explicit pitch sequence and supervised by a frozen pitch transcriber.
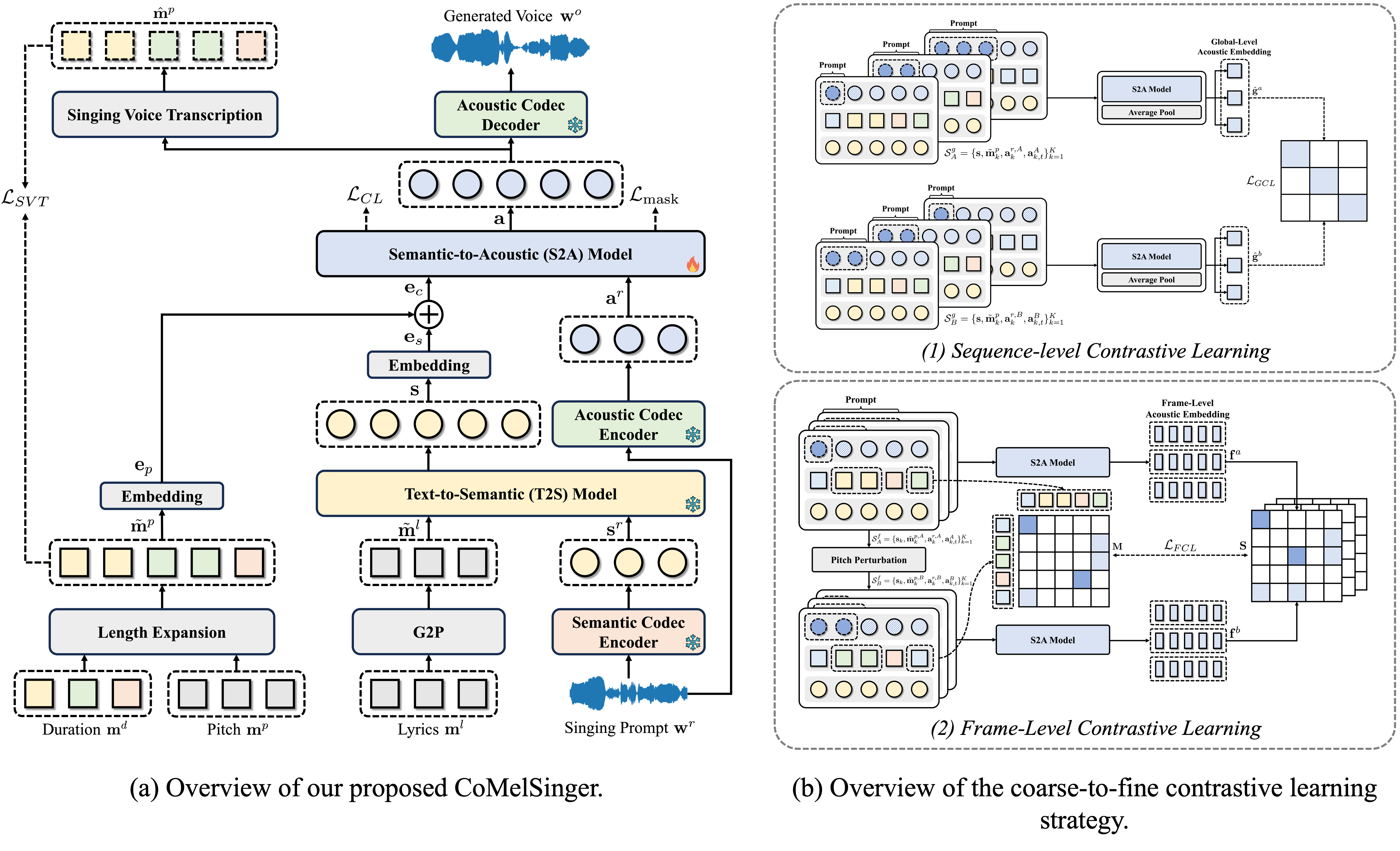
One operates over a whole phrase, one frame by frame — together they pull melody and timbre apart.
Four objective metrics and three subjective ones, on both the seen-singer and zero-shot test sets. Numbers are taken directly from the paper. Within non-GT systems, bold marks the best result and underlining marks the second best.
RMSE between generated and reference pitch contours — the direct test of melody control.
WavLM speaker-embedding cosine similarity — how closely timbre matches the prompt.
Mel-cepstral distortion between synthesized and reference audio — overall spectral fidelity.
A learned, reference-free model of perceived singing quality.
50 utterances each from Opencpop and M4Singer · vocoder fixed to HiFi-GAN across all systems
| Model | MOS-Q | MOS-N | SMOS | MCD | F0-RMSE | SingMOS | SECS |
|---|---|---|---|---|---|---|---|
| GT | 4.17 | 4.38 | 4.41 | – | – | 4.37 | 0.925 |
| GT (acoustic codec) | 4.01 | 4.19 | 4.48 | 0.93 | 0.012 | 4.31 | 0.906 |
| DiffSinger | 3.68 | 3.79 | 3.86 | 4.59 | 0.084 | 4.13 | 0.769 |
| VISinger2 | 3.59 | 3.86 | 3.91 | 5.36 | 0.061 | 4.15 | 0.792 |
| StyleSinger | 3.67 | 3.92 | 4.11 | 4.95 | 0.112 | 4.19 | 0.833 |
| SPSinger | 3.81 | 4.10 | 4.06 | 4.28 | 0.054 | 4.28 | 0.860 |
| Vevo 1.5 | 3.85 | 3.96 | 4.17 | 4.18 | 0.051 | 4.39 | 0.907 |
| CoMelSinger (ours) | 3.90 | 4.02 | 4.22 | 4.17 | 0.042 | 4.32 | 0.912 |
CoMelSinger gets the lowest F0-RMSE and highest SMOS/SECS of any system in the comparison — strongest melody accuracy and timbre consistency together, approaching the GT-through-codec upper bound.
10 male + 10 female unseen singers from OpenSinger, paired with M4Singer score sequences · MCD omitted — no ground-truth alignment exists in this setting
| Model | MOS-Q | MOS-N | SMOS | F0-RMSE | SingMOS | SECS |
|---|---|---|---|---|---|---|
| GT | 4.20 | 4.35 | 4.55 | – | 4.41 | 0.932 |
| GT (acoustic codec) | 4.07 | 4.22 | 4.32 | 0.015 | 4.66 | 0.921 |
| DiffSinger | 3.75 | 3.72 | 3.25 | 0.098 | 4.11 | 0.658 |
| VISinger2 | 3.72 | 3.74 | 3.31 | 0.074 | 4.08 | 0.704 |
| StyleSinger | 3.48 | 3.82 | 3.85 | 0.125 | 4.22 | 0.853 |
| SPSinger | 3.92 | 4.03 | 3.76 | 0.065 | 4.29 | 0.844 |
| Vevo 1.5 | 3.72 | 3.81 | 4.02 | 0.094 | 4.16 | 0.870 |
| CoMelSinger (ours) | 3.87 | 4.11 | 4.14 | 0.048 | 4.25 | 0.897 |
Baselines drop noticeably on SMOS, SECS, and F0-RMSE for unseen singers; CoMelSinger holds up with only minimal degradation from the seen-singer setting.
Seen-singer test set · CL = coarse-to-fine contrastive learning (SCL + FCL) · SVT = pitch-guidance module · "−CL+SVT" is the plain MaskGCT-based SVS baseline
| Configuration | MCD | F0-RMSE | SingMOS | SECS |
|---|---|---|---|---|
| CoMelSinger | 4.17 | 0.042 | 4.32 | 0.912 |
| − CL | 4.91 | 0.080 | 4.12 | 0.895 |
| − SCL only | 4.53 | 0.062 | 4.25 | 0.900 |
| − FCL only | 4.82 | 0.075 | 4.18 | 0.892 |
| − SVT | 5.53 | 0.194 | 3.95 | 0.883 |
| − CL + SVT | 5.89 | 0.210 | 3.83 | 0.874 |
Removing SVT hurts F0-RMSE the most (0.042 → 0.194); removing FCL hurts pitch detail more than removing SCL hurts timbre — consistent with their intended roles.
The target contour provides the reference structure used to judge melody fidelity.
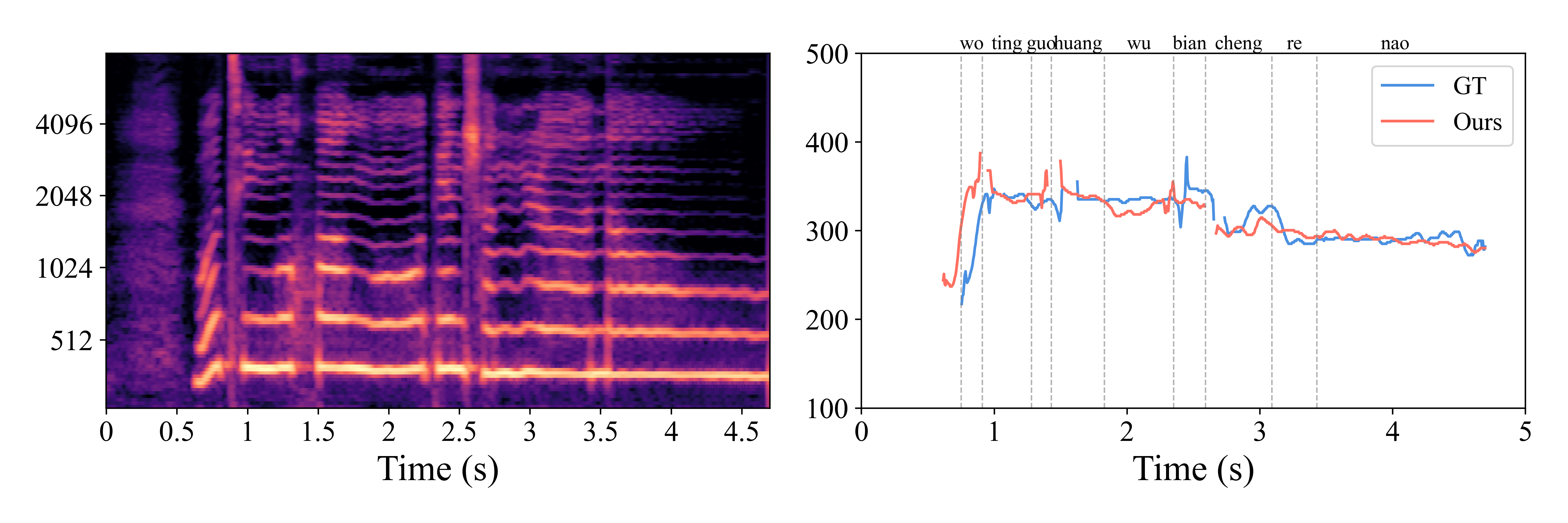
The predicted trajectory tracks the reference closely while preserving the prompted timbre.
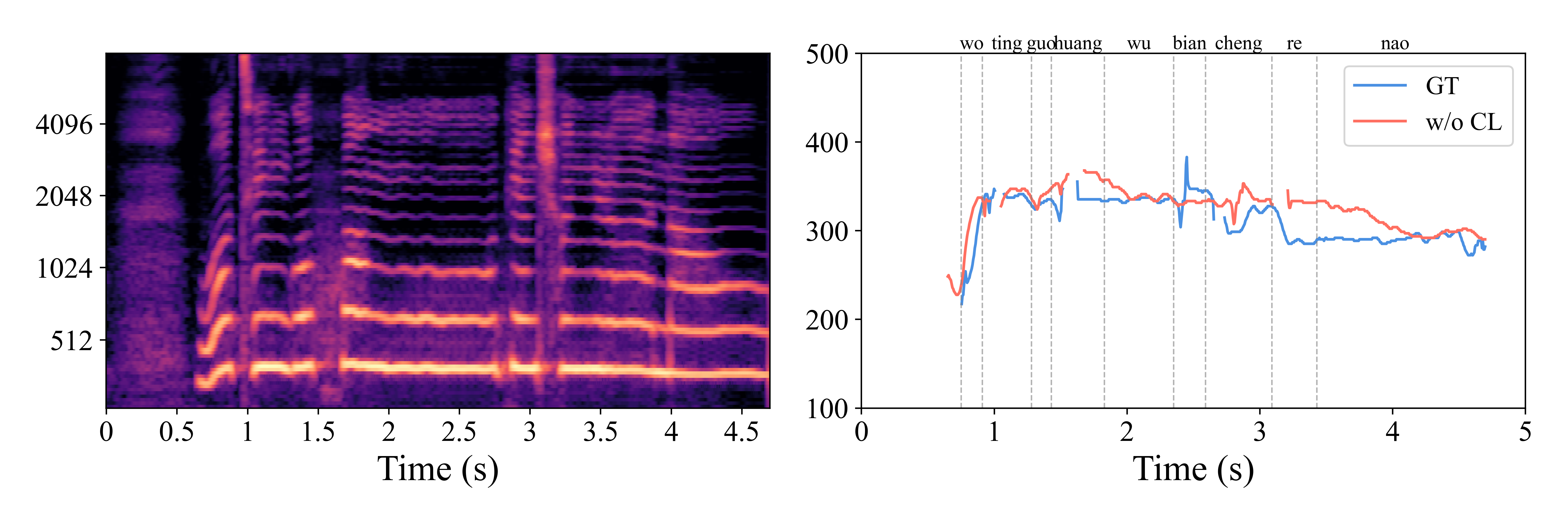
Removing CL weakens the melody-timbre separation and visibly destabilizes local pitch detail.
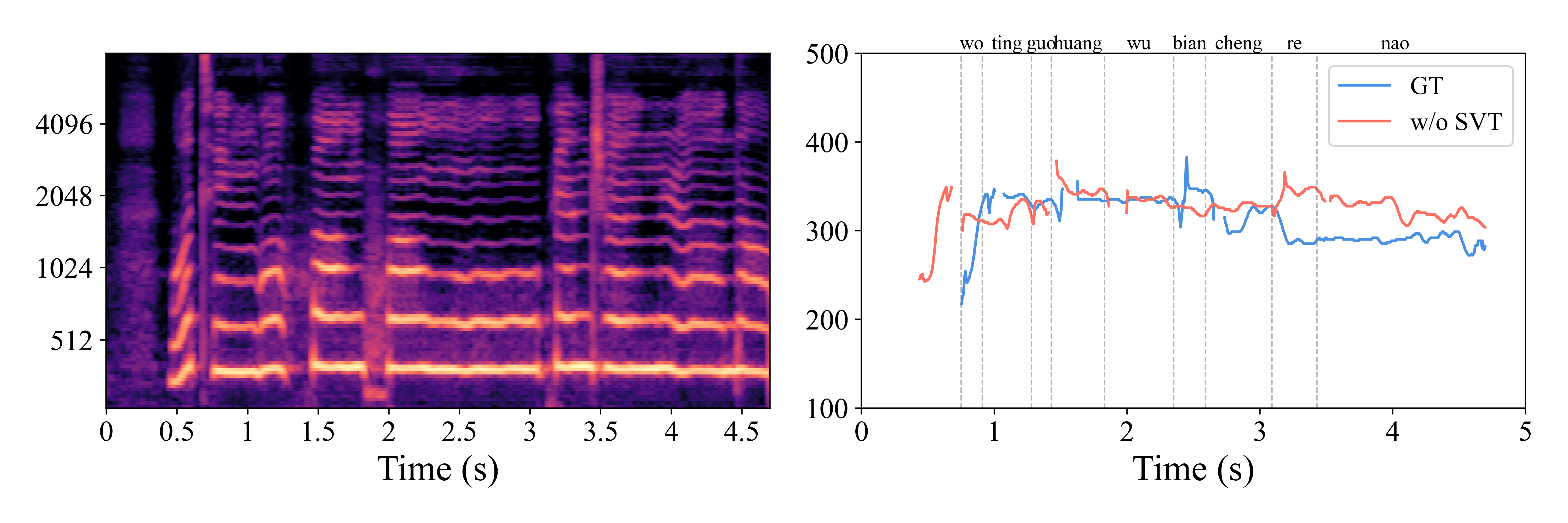
The largest F0-RMSE jump in Table V aligns with this degraded pitch trajectory.
GT is the ground-truth recording re-synthesized through the codec, so it bounds what any codec-based system could possibly reach. Reference is the acoustic prompt. CoMelSinger is highlighted throughout.
No ground truth exists here — these singers' voices come only from a few seconds of speech-like prompt audio. The melody sparkline shows the real pitch sequence each system was asked to follow.