Co-speech gesture generation aims to synthesize realistic body movements that are semantically coherent with speech and faithful to a user-specified gestural style. Existing VQ-VAE based co-speech gesture generation methods improve generation quality but fail to encode semantic structure into the motion representation or explicitly disentangle content from style, limiting both semantic coherence and personalization fidelity. We present PersonaGest, a two-stage framework addressing both limitations. In the first stage, a semantic-guided RVQ-VAE disentangles motion content and gestural style within the residual quantization structure, where a Semantic-Aware Motion Codebook (SMoC) organizes the content codebook by gesture semantics and contrastive learning further enforces content-style separation. In the second stage, a Masked Generative Transformer generates content tokens via a semantic-aware re-masking strategy, followed by a cascade of Style Residual Transformers conditioned on a reference motion prompt for style control. Extensive experiments demonstrate state-of-the-art performance on objective metrics and perceptual user studies, with strong style consistency to the reference prompt.
Motivation
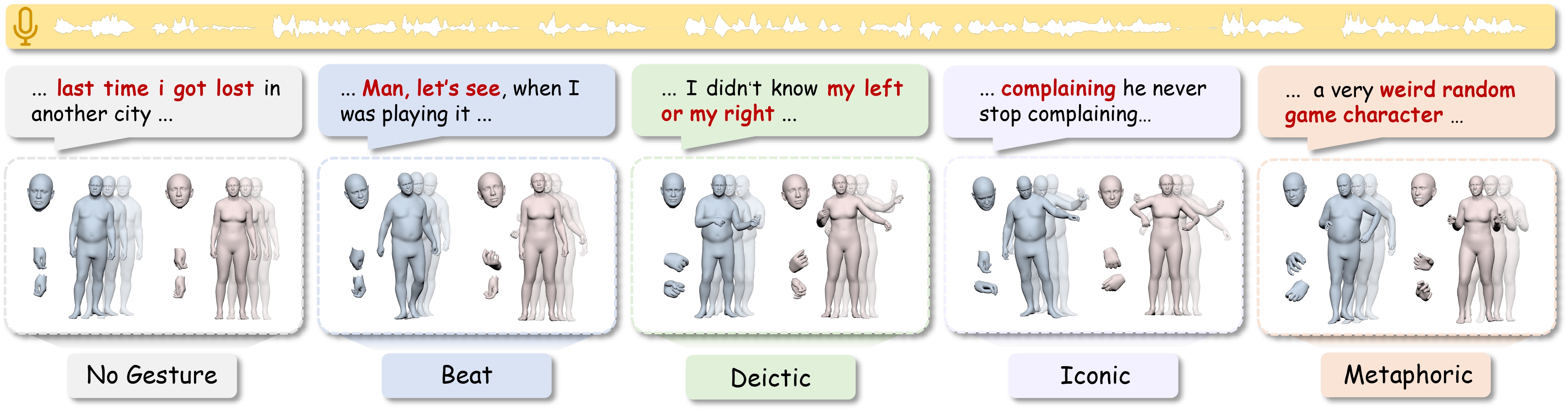
Prior methods encode gesture style as a global attribute, failing to separate what gesture to make from how to make it. PersonaGest explicitly disentangles content and style within a hierarchical motion representation, enabling both semantic coherence and personalization fidelity.
Comparison with baselines on free-form co-speech gesture generation · zero-shot unseen speaker
Comparison with style-conditioned baselines · zero-shot unseen speaker
Each sample is conditioned on two complementary style references, with upper body, hands, and lower body styles independently sourced from different speakers.
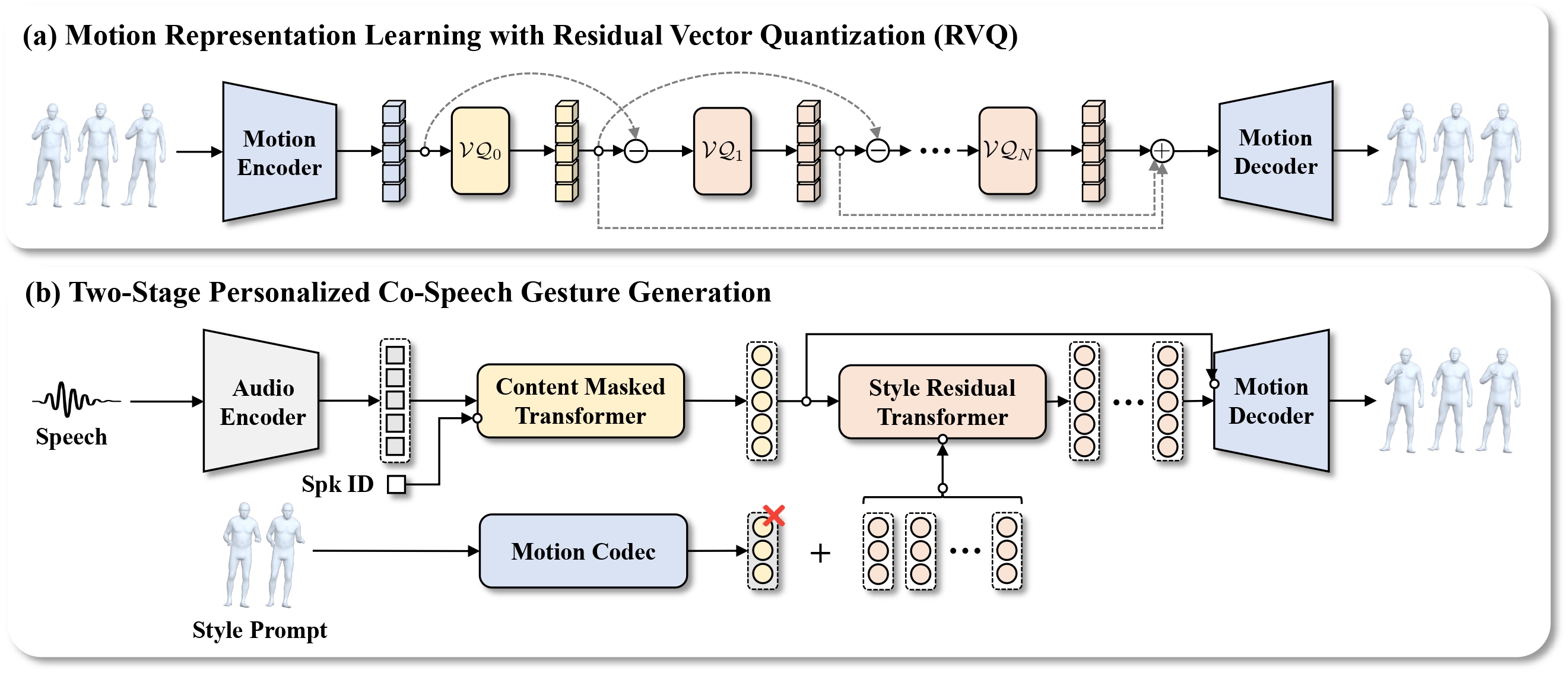
Overview of PersonaGest. Stage 1 A semantic-aware RVQ-VAE encodes motion into disentangled content and style latent codes. Stage 2 A Content Masked Transformer generates content tokens conditioned on speech and speaker identity, followed by a Style Residual Transformer that generates style tokens conditioned on a reference motion prompt.
Stage 1
Semantic-Aware RVQ-VAE
The first stage disentangles motion content and gestural style within the residual quantization structure. A Semantic-Aware Motion Codebook (SMoC) organizes the content codebook by gesture semantics, and contrastive learning further enforces content-style separation.
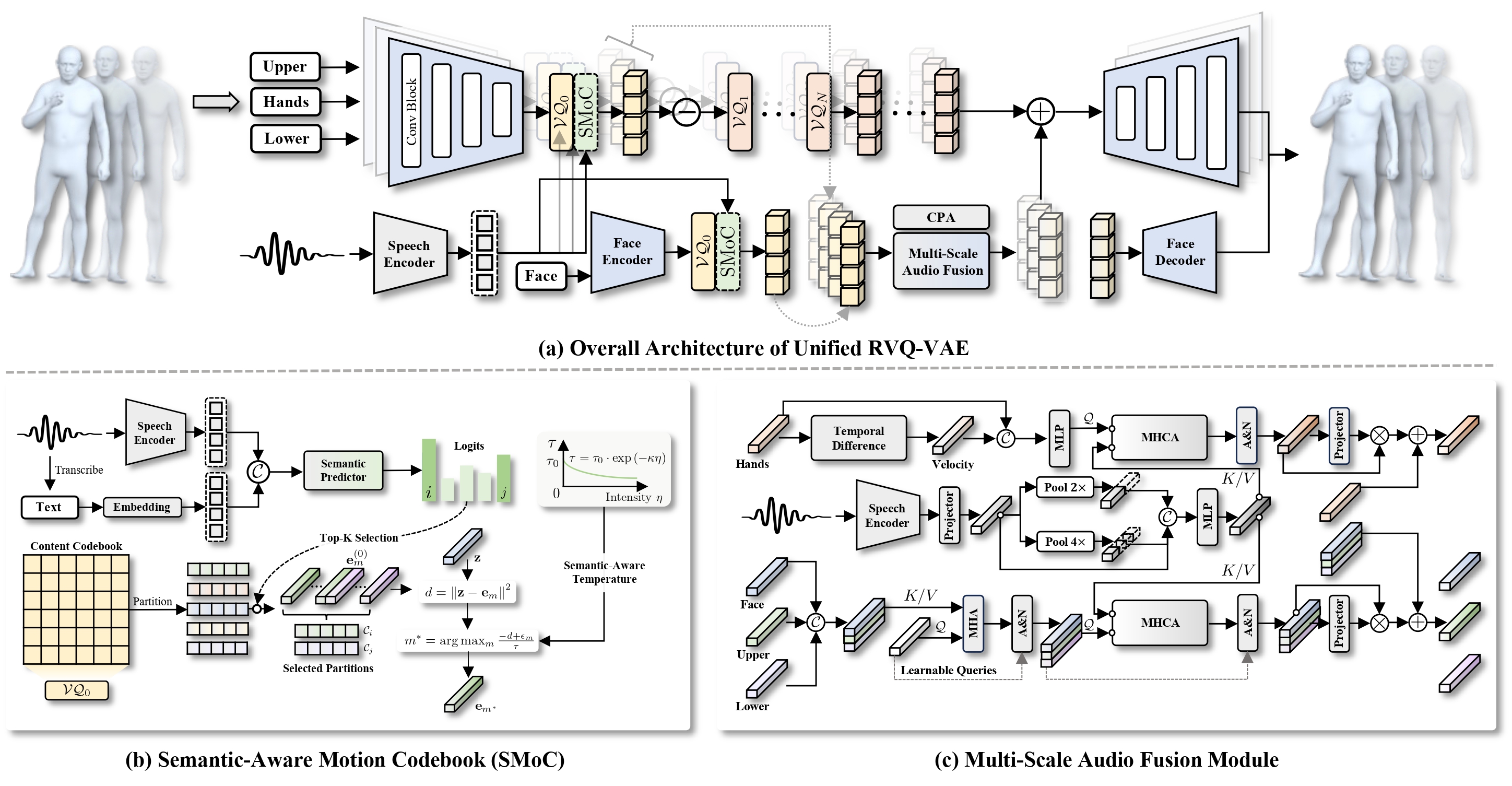
Stage 2
Gesture Generation
The second stage generates content tokens via a Masked Generative Transformer with a semantic-aware re-masking strategy, followed by a cascade of Style Residual Transformers conditioned on a reference motion prompt for style control.

| Model | FGD ↓ | FGDsk ↓ | BC ↑ | Diversity ↑ |
|---|---|---|---|---|
| EMAGE | 3.667 | 4.080 | 0.812 | 12.116 |
| MambaTalk | 3.706 | 3.752 | 0.807 | 10.743 |
| EchoMask | 3.172 | 5.268 | 0.800 | 13.881 |
| SemTalk | 3.578 | 4.296 | 0.807 | 11.788 |
| PyraMotion | 2.411 | 3.761 | 0.678 | 8.637 |
| GestureLSM | 2.949 | 3.928 | 0.725 | 7.600 |
| PersonaGest Ours | 2.311 | 2.660 | 0.826 | 11.970 |
| Model | FGD ↓ | FGDsk ↓ | BC ↑ | Diversity ↑ |
|---|---|---|---|---|
| SynTalker | 3.268 | 3.242 | 0.687 | 10.233 |
| ZeroEGGS | 2.875 | 3.779 | 0.717 | 3.274 |
| PersonaGest Ours | 2.617 | 2.726 | 0.815 | 8.985 |
Bold = best · underline = second best · scaled as in paper
21 participants rated on a 5-point Likert scale (higher is better)
| Model | JRMSE ↓ | MSE ↓ | LVD ↓ |
|---|---|---|---|
| VQ-VAE | 1.637 | 3.900 | 3.850 |
| APVQ-VAE | 0.933 | 3.110 | 3.520 |
| RVQ-VAE (S) | 0.345 | 0.814 | 1.890 |
| RVQ-VAE (B) | 0.421 | 1.200 | 2.310 |
| PersonaGest Ours | 0.326 | 0.809 | 1.880 |
Bold = best · underline = second best · scaled as in paper
Runtime per second of generated motion (s/s) on a single NVIDIA A100 GPU. PersonaGest runs at ~26× real-time, while reaching the best overall generation quality among style-conditioned baselines.
Mean shown in cards · ± std as in paper · single NVIDIA A100 GPU
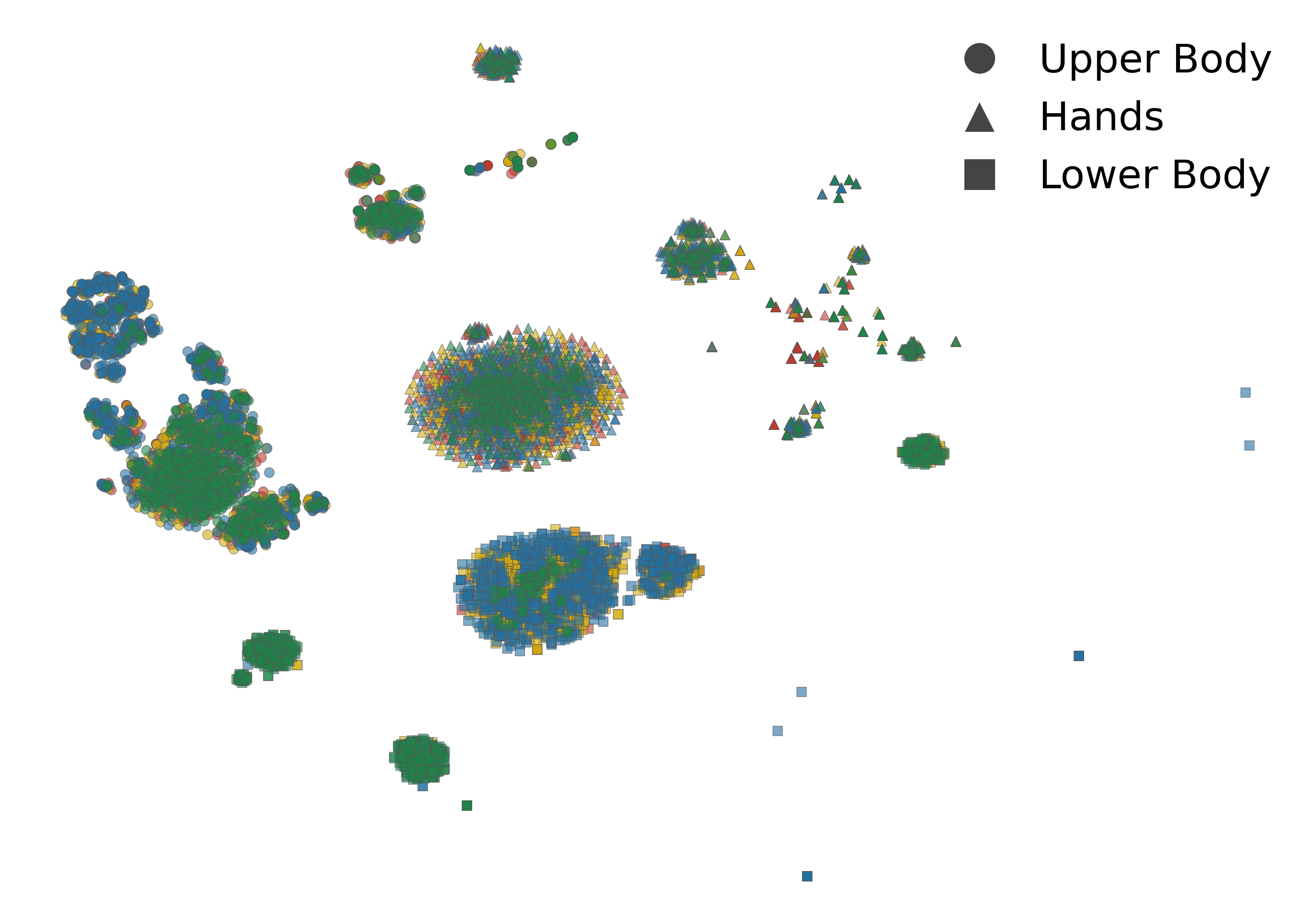
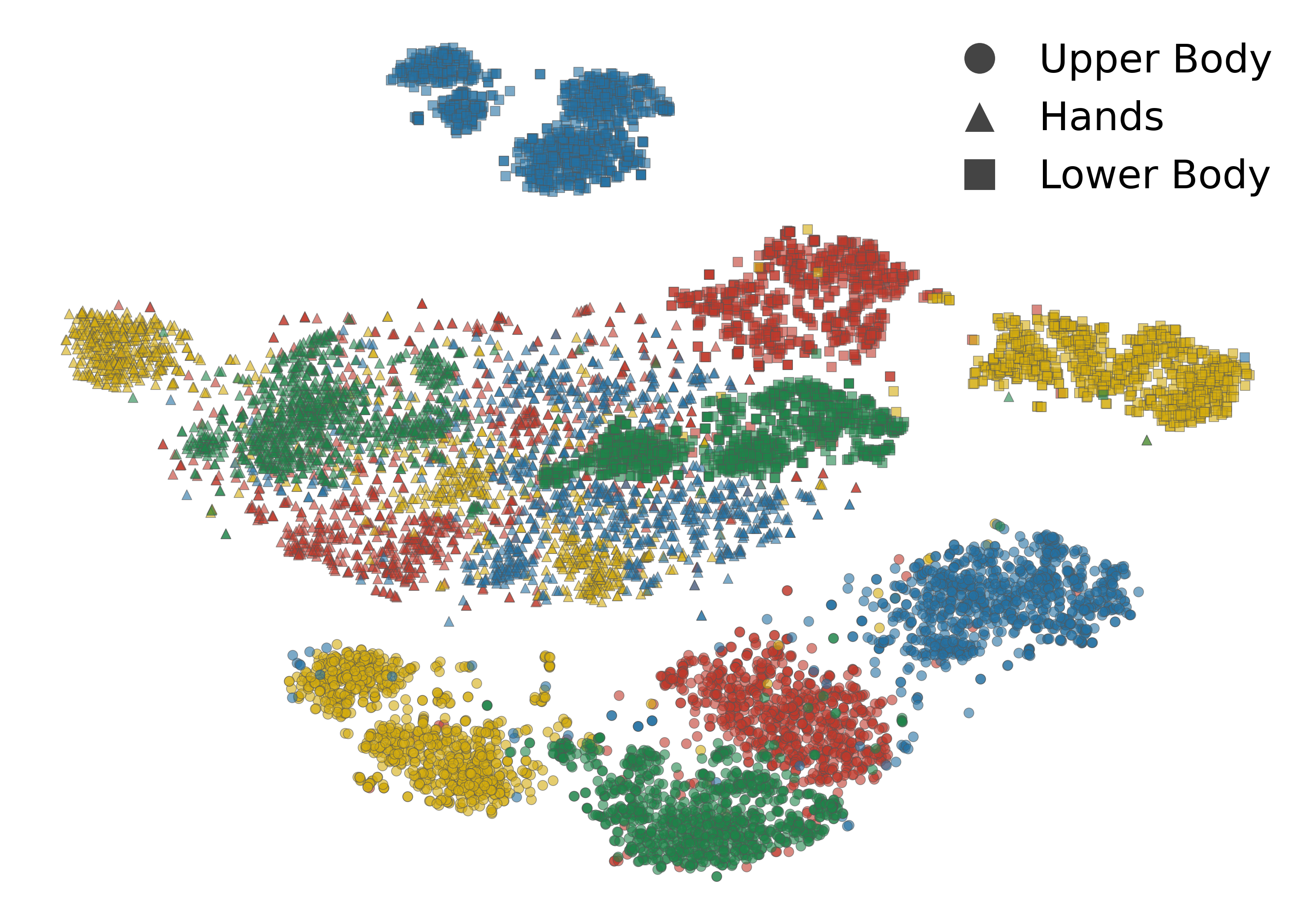
Colors denote different speakers. Content representations interleave across speakers; style representations form well-separated speaker clusters.